
While AIs continue to break new records, a quieter revolution is taking shape in the Big Data sphere: the open data revolution.
Following the French law for a Digital Republic of 2016, France is now reaping the benefits of its strategy. Indeed, according to Capgemini, France is the best European student in terms of open data.
These fruits are reflected, for example, in the appearance of the National Buildings Database (BNDB Base Nationale Des Bâtiments), which was released in April 2022. This database brings together various data sources on buildings in order to build a complete profile for each building. The appearance of this database is conditioned by the preliminary existence of multiple open data sources.
This article aims to present the French open data databases we have worked with, the quality of their data and possible use-cases that we can have.
Open data bases in France
During our various projects, we have been able to interact with various open data sources. These include :
- The SIRENE database (Système national d’identification et du répertoire des entreprises et de leurs établissements),
- The National Buildings Database (BNDB),
- Data sources from INSEE (National Institute of Statistics and Economic Studies),
- SYNOP data from Météo France,
- The National Address Database (BAN).
This first part aims to present each database, the quality of their data and different use cases that could be applied.
1- The National Buildings Database (BNDB)
Presentation of the BNDB
The BNDB is a recently launched database. Launched in April 2022 for the needs of the Go-Rénove project, it contains a wealth of information about buildings. It exists in several versions depending on the sensitivity of the data concerned. The open version contains basic information such as the floor area of the building, its height, its address, the year of construction, its use,etc.
More sensitive versions are then reserved for “landowners”, in this case public institutions such as local authorities. These data include the living area of a house, the presence of a swimming pool, the number of bathrooms and other data with a similar level of accuracy.
BNDB’s quality
The BNDB is managed by the CSTB (Centre Scientifique et Technique du Bâtiment). Its data is very complete with the vast majority of its columns above 95% completeness. 83% of street numbers are present. The other data are much more complete with a completion rate of around 95%. When there is ambiguity (for example, two addresses for the same building) the BNDB indicates this and lists the different possible addresses. 95% of the addresses are associated with a single building, which facilitates data linkage to other databases.
Despite these strengths, there are still inconsistencies in the database. Some addresses may be erroneous, heights and floor areas of buildings may have absurd values (for example buildings less than 2m high). Geocoding may also be deficient, although a column is provided for this purpose to qualify the quality of the latter.
Use cases
Various use cases can be considered:
- Referencing of Energetic Performance Diagnosis (DPE) in order to encourage or assist in the thermal renovation of housing (Go-Rénove project),
- Comparison of electricity, gas and water consumption habits according to building characteristics,
- Proposals for bank loans for the renovation of poorly insulated houses,
- Banks and insurance companies can also propose credit or insurance offers for customers concerned by energy renovation of their houses,
- We should also note the emergence of B2E (“Business to Employees”) applications to enable companies to find out which employees could benefit from aid for the energy renovation of their homes.
2- SIRENE Database
Presentation of the SIRENE database
The SIRENE database lists all French companies and their various establishments. Each company is identified by its SIREN number and each establishment is identified by its SIRET number, the latter being formed in part by the SIREN number.
It lists various information about the establishments such as their size, number of employees, sector of activity, etc. And each establishment is located by its address.
SIRENE database’s quality
The SIRENE database has many empty columns. Its exploitable parts are the address, the establishment’s activity , and essential information such as the SIRET number or the NIC. The number of employees is also usable to a lesser extent, with a completion rate of 14%. The rest of the data does not exceed 10% completeness and is therefore difficult to use.
The SIRENE database thus contains sufficient data to characterize active establishments and their type of activity. However, it also contains some specificities that makes it difficult to use:
- This database is partly constructed on declarations. Anyone can declare themselves as an entrepreneur and set up their own company, which will be listed at their personal address, which creates shadow establishments. The solution is to look at the number of employees declared, but given its 14% completion rate, the impact is limited. The type of activity can then be used to keep only a certain typology of establishments that are not likely to be shadow establishments, such as restaurants.
- This database can also have a lack of precision. On data such as the type of activity or the number of employees in the establishment, it is not uncommon for the observed reality to be different. Google Maps photos at different dates do not always match with the SIRENE database. Some establishments do not exist, others are undersized or do not correspond to the establishment observed. It would be interesting to compare the information in the SIRENE database with information from another data source (e.g. from the APIs made available by Google Maps).
Use cases
The SIRENE database can be used in a number of ways:
- Analysis of activities already present in a district to target the establishment of a new business (e.g. choice of district for a new restaurant),
- Targeting professional clients to offer them insurance policies adapted to their location (risk of flooding, events, etc.),
- For all B2B companies, it enables them to get to know their customers better by crossing internal data with SIRENE data.
3- INSEE databases
Presentation of the databases distributed by the INSEE
INSEE distributes a large number of databases. These include various national statistics at different scales, the most precise being the IRIS (Ilot Regroupé pour l’Information Statistique) which is a sub-municipal division established in 1999 in order to disseminate the population census (each IRIS having an approximate population of 2,000 people).
We can find classical census data but also other interesting statistics such as median income, age distribution, distribution of secondary/main residences, unemployment rate, etc.
These data, too numerous to be listed here, make it possible to establish a socio-economic context for a building, as for example, knowing whether a building is located in a wealthy neighborhood or not.
INSEE databases’ quality
Regarding INSEE’s data, our various explorations have shown that it has very good completion rates. For example, the data on IRIS’ population has a completion rate of 100%. In general, a large majority of the columns we have worked with have a completion rate of over 99%. The INSEE data therefore appear to be of very good quality.
However, given the multiplicity of available sources, it is possible to have databases of lower quality, but this remains to be proven.
Use cases
- Area targeting for new shops (luxury shop in an affluent area, area targeting by population, etc.),
- Adapting public facilities in a neighborhood to the age distribution of its inhabitants.
4- Weather database SYNOP
Presentation of the SYNOP database
The SYNOP database contains observation data from international messages circulating on the World Meteorological Organisation’s global telecommunication system. Various measured parameters are available from January 1996 to the present day, such as temperature, rainfall, humidity, wind direction and strength, and atmospheric pressure. It also contains parameters observed from the earth’s surface such as sensitive weather, cloud description, visibility, etc.Other parameters are also available depending on the region (typically snow height).
SYNOP data’s quality
SYNOP data show good completion rates, above 97%, for “classical” meteorological measurements (temperature, humidity, pressure, precipitation, etc.). Other more anecdotal measurements have lower completion rates but are not a sign of poor data quality, as for example presence of clouds or snow.
Since our study focuses on recent data (from 2019), some data may not be available for previous years.
Use cases
- Modeling of electricity, gas and water consumption,
- Optimisation of building renovation plans,
- Modeling of seasonal clothing sales.
5- National address database (BAN)
Presentation of the BAN database
The BAN was created on 15 April 2015 thanks to the alliance of various actors:
- IGN
- La Poste Group
- OpenStreetMap France (association under the law of 1901)
- The Etalab mission (Prime Minister’s department in charge of Open Data in France)
Its purpose is to list all the addresses on French territory, particularly for standardization purposes. It currently contains more than 25 million addresses on French territory.
The BAN is also accompanied by an API that enables the recovery of a standardized address from an address field that is not standardized. For example it can transform the address “21 R Berri Paris” into “21 rue de Berri 75008 Paris”, which opens up a number of possibilities that we will detail shortly.
The BAN also contains coordinates, which make it possible to locate addresses spatially. This makes it possible, for example, to know in which IRIS an address is located (Ilôts Regroupés pour l’Information Statistique de l’INSEE).
BAN’s data quality
Through our various manipulations of the BAN we have been able to appreciate the reliability of this database as well as of its API. With very good completion rates, it meets most expectations.
However, there are a few problems with geocoding and poorly written addresses. For example, it is not always possible to locate an address in Google Maps or in our databases. Some addresses also exist in different versions. These defects seem to concern rural areas where the population density is lower, whereas the quality of addresses is higher in urban areas.
Use cases
- Linking different databases by addresses,
- Standardization of addresses within a database in order to maximize the mail delivery rate,
- Geocoding of addresses for geographical representation or analysis.
Conclusion on existing french open databases
To conclude this section, the databases currently present in France are diverse and varied. They cover a wide range of different information, which gives them multiple applications. In this article, we have covered some of the databases available in open data. Many other data sources are accessible on “data.gouv” and cover many other areas. Other open data players are also involved in the spreading of open data, such as OpenDataSoft.
The quality of open data can vary from one source to another. This variation in quality depends on the organization responsible for managing the data, but also on the nature of the data. For example, the INSEE can produce quality data on macroeconomic statistics but can also produce data of lesser quality, as in the case of the SIRENE database, which depends largely on the declarations’ accuracy of the companies concerned.
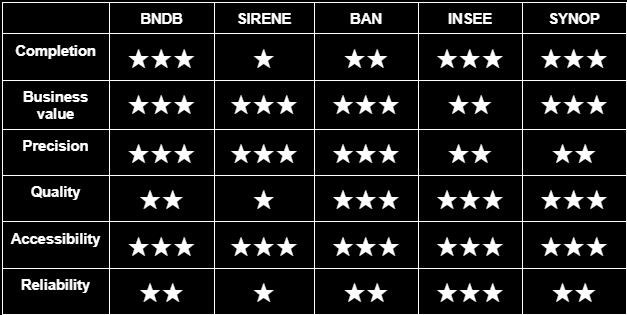
You can find below a table summarizing the qualities and defaults of the various databases available.
The construction of augmented profiles using address-based joining
Thanks to the BAN API, addresses are no longer a simple text field filled with capital letters and other typing errors, but become standardized data. It is thus possible to join different databases by their addresses. It should be noted, however, that addresses must be complete and include the street number. One of the first obstacles to the use of addresses as a merge key is the lack of street numbers.
Thus, all the data presented above can be grouped around an address, namely
- Buildings data,
- SIRENE data on establishments,
- Information on the district and municipality in which the address is located (socio-demographic statistics),
- SYNOP weather data,
- Calendar data (holidays, public holidays, etc.),
- And any other internal company data that is identified by an address.
The connection at the address level makes it possible to join all the geographical levels from the building to the municipality data.
The result is a dataset that fully describes the context of each building. This context then allows us to explain or model a target variable, for example electricity consumption, by taking into account the interactions between different variables. More advanced statistical techniques such as Machine Learning algorithms are then more appropriate due to the complexity of the datasets built, and can reveal and quantify the relationships between different phenomena. For example, the combination of a high temperature and a large living area can result in a significant increase in the electricity consumption of a household.
Finally, for some public organizations, access to this augmented data allows them to better manage the facilities in a territory as well as to make certain checks on the declarations made by citizens more accurate, particularly the declarations on the characteristics of the household. In addition, as public bodies have access to more accurate versions of existing data, they can havemore value from the use of this data.
Conclusion
Open data is becoming more and more mature in France, and it is now possible to easily build relatively complete and accurate datasets throughout France. Some companies are already using the richness of this data, such as namR, which combines it with data from other sources and Artificial Intelligence-based processing (using satellite images, for example) in order to construct the most complete building profiles possible.
At Sia Partners we share the belief that open data is a force that our clients can use for new value-added applications. Open data is a new lever that will continue to evolve and that companies can use to enrich their data panels. This is why we strive to be constantly on the lookout for Open Data in order to develop know-how in this area.We have also implemented a ready-to-use Open Data warehouse in order to bring this value to our clients as quickly as possible.
